2Chapter 2: Basics of SFA for cross-sectional data
2.1 Exercise 2.1 Data Import
This exercise demonstrates importing the data file cowing.xlsx in Python using the Pandas read_excel function. After importing, we display the first two lines and the last line of the data set.
import pandas as pdimport numpy as np data = pd.read_excel('cowing.xlsx', index_col=[0]) # use the first column of the excel file as the indexdata.columns = ['lnY','lnK','lnF', 'lnL', 'P_K', 'P_F', 'P_L']data.index.name ='Utility'# The index column is the utility firmdisplay(data.head(2))display(data.tail(1))
lnY
lnK
lnF
lnL
P_K
P_F
P_L
Utility
1
6.955593
16.312510
16.348255
11.849398
0.0338
0.197
1.590003
2
7.255591
16.916638
16.507648
11.338572
0.0350
0.254
2.050000
lnY
lnK
lnF
lnL
P_K
P_F
P_L
Utility
111
5.267858
16.148819
14.677869
11.127263
0.0288
0.362
1.49
# Remove all previous function and variable definitions before the next exercise%reset
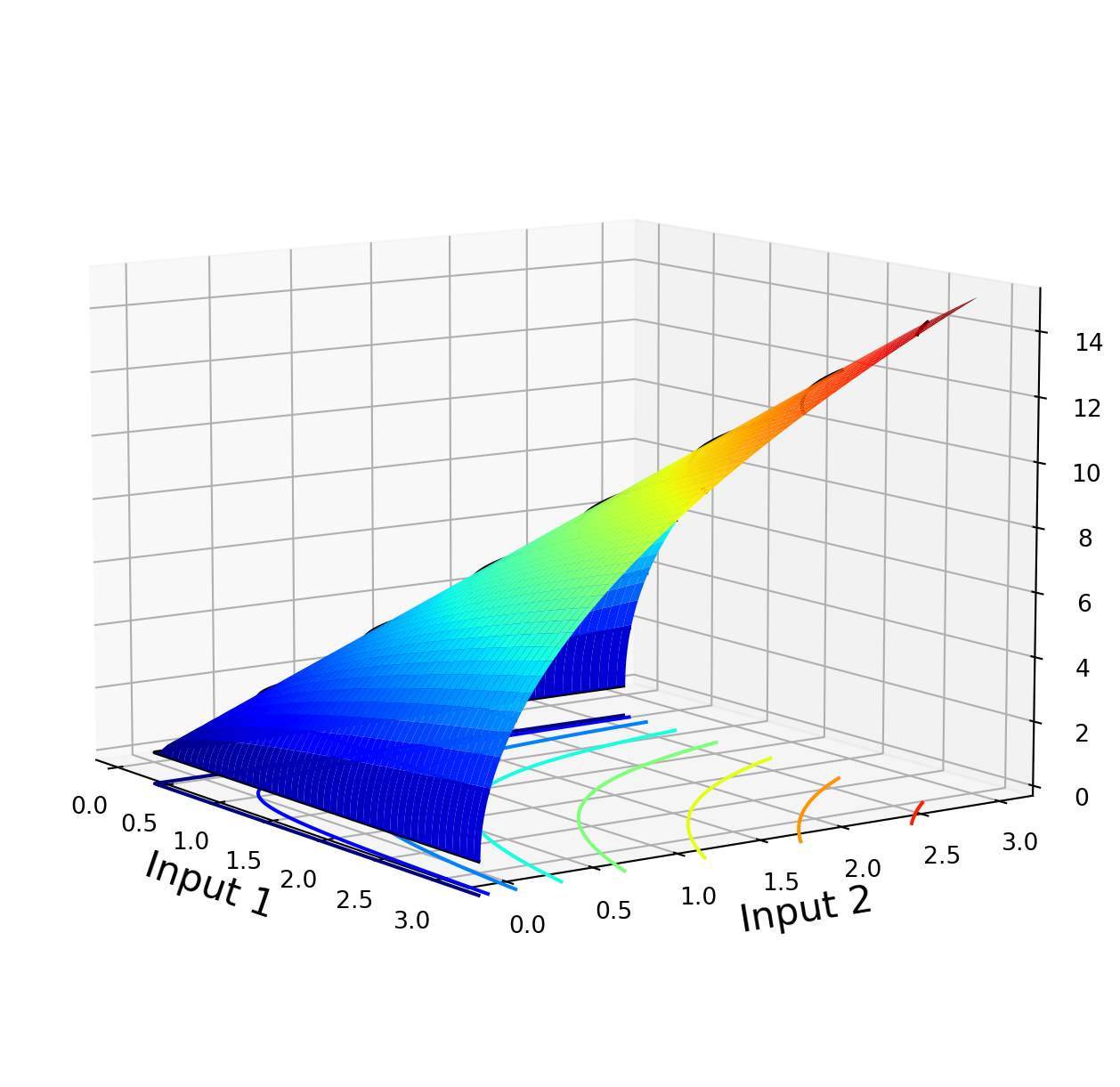
2.2 Exercise 2.2: Plotting a two-input production function surface
In this exercise, we plot the surface for a two-input Cobb-Douglas production function.
import matplotlib.cm as cmimport matplotlib.pyplot as pltimport numpy as npfrom mpl_toolkits.mplot3d import Axes3Ddef CobbDouglas(beta, X, Y):return5* X**beta * Y ** (1- beta)
x = np.linspace(0, 3, 1000)y = np.linspace(0, 3, 1000)X, Y = np.meshgrid(x, y)output = CobbDouglas(beta=0.5, X=X, Y=Y)fig, ax = plt.subplots(figsize=(10, 8), subplot_kw={"projection": "3d"})surf = ax.plot_surface(X, Y, output, cmap=cm.jet)ax.contour(X, Y, output, 8, cmap=cm.jet, linestyles="solid", offset=-1)ax.contour(X, Y, output, 8, colors="k", linestyles="solid")ax.set_xlabel("Input 1", fontsize=16)ax.set_ylabel("Input 2", fontsize=16)ax.set_zlabel("Output", fontsize=16)ax.view_init(10, -35)plt.show()
# Remove all previous function and variable definitions before the next exercise%reset
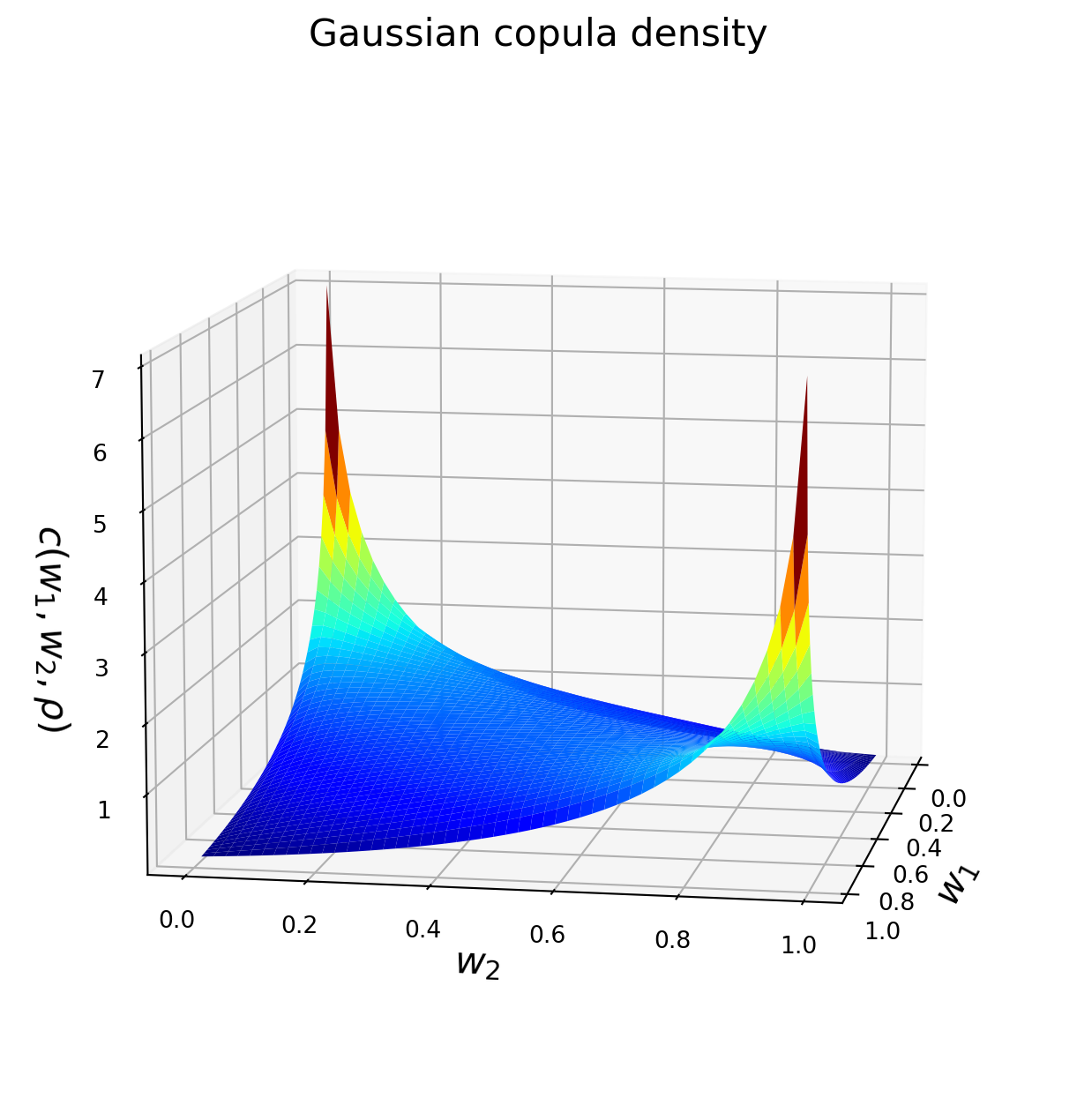
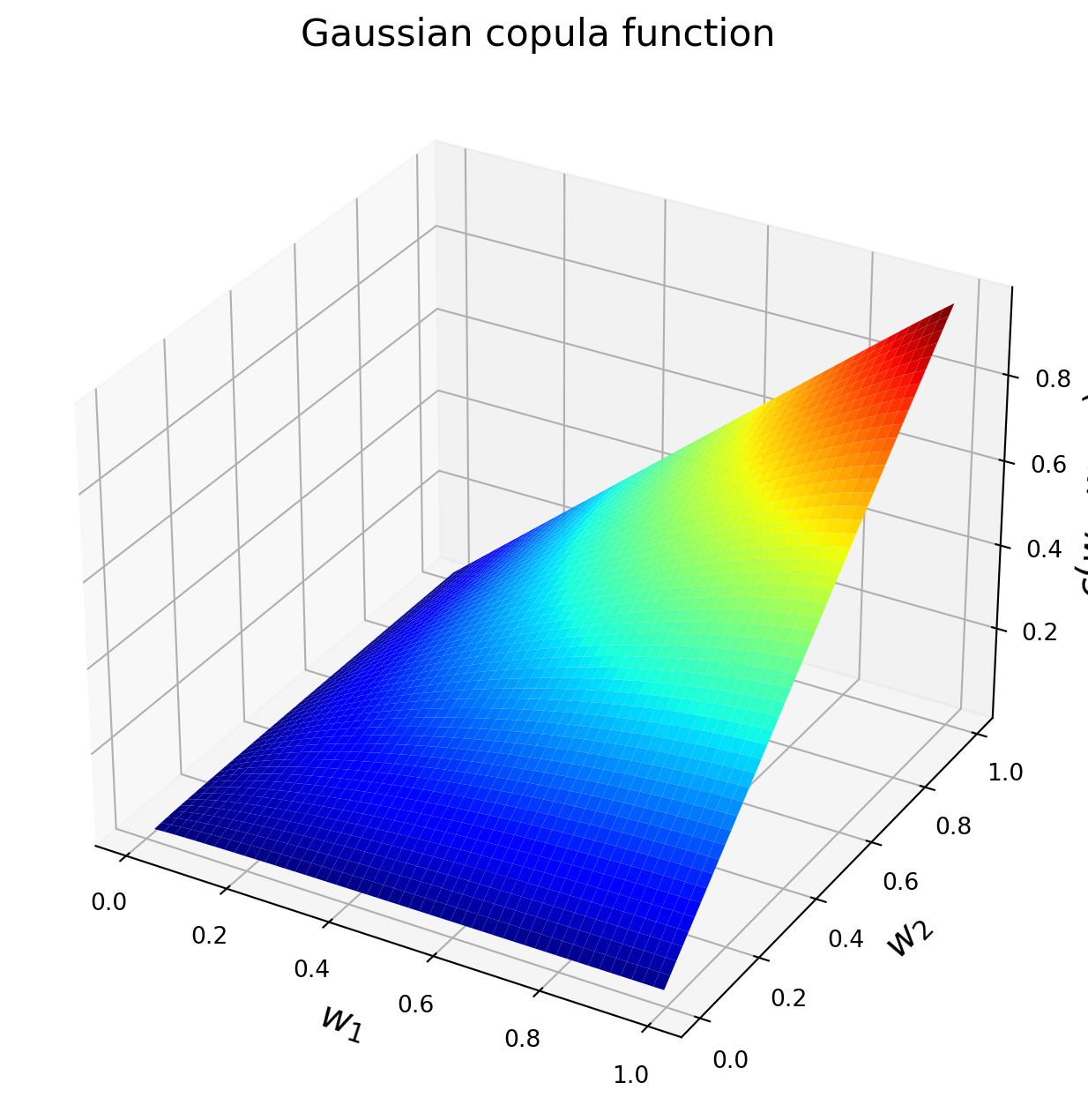
2.3 Exercise 2.3: Plotting a bivariate Gaussian Copula
In this exercise, we plot the bivariate Gaussian copula density and distribution function with \(\rho = 0.5\).
import matplotlib.cm as cmimport matplotlib.pyplot as pltimport numpy as npfrom mpl_toolkits.mplot3d import Axes3Dfrom scipy import stats
# Remove all previous function and variable definitions before the next exercise%reset
2.4 Exercise 2.4: Corrected Ordinary Least Squared (COLS) for deterministic frontier of the U.S. utilities data
In this exercise we implement a Corrected OLS (COLS) using a Cobb-Douglas production function.
The coefficient estimates suggest an increasing return to scale in electricity generation. The sign on labour (\(\beta_{3}\)) is surprising, but that coefficient is statistically insignificant.
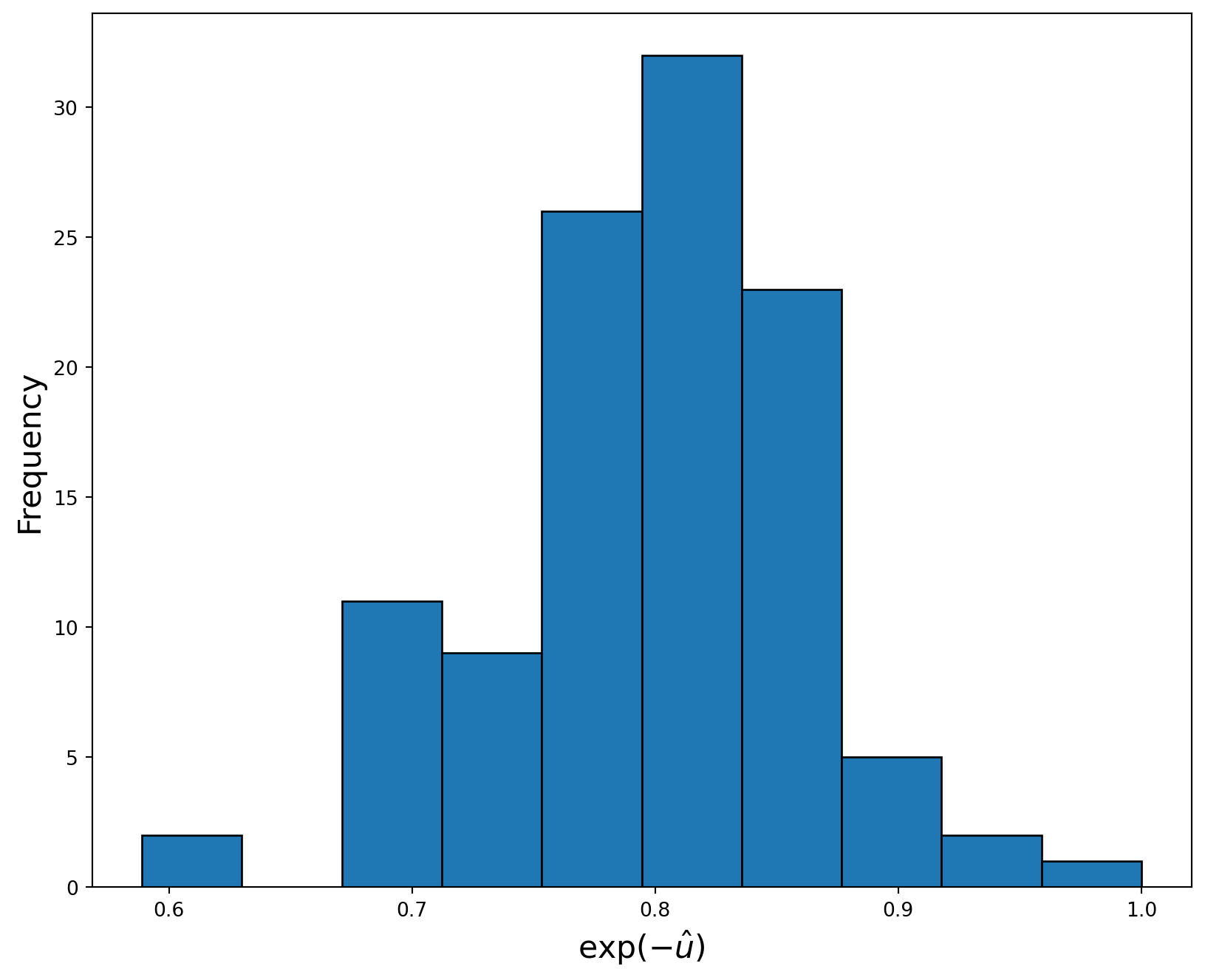
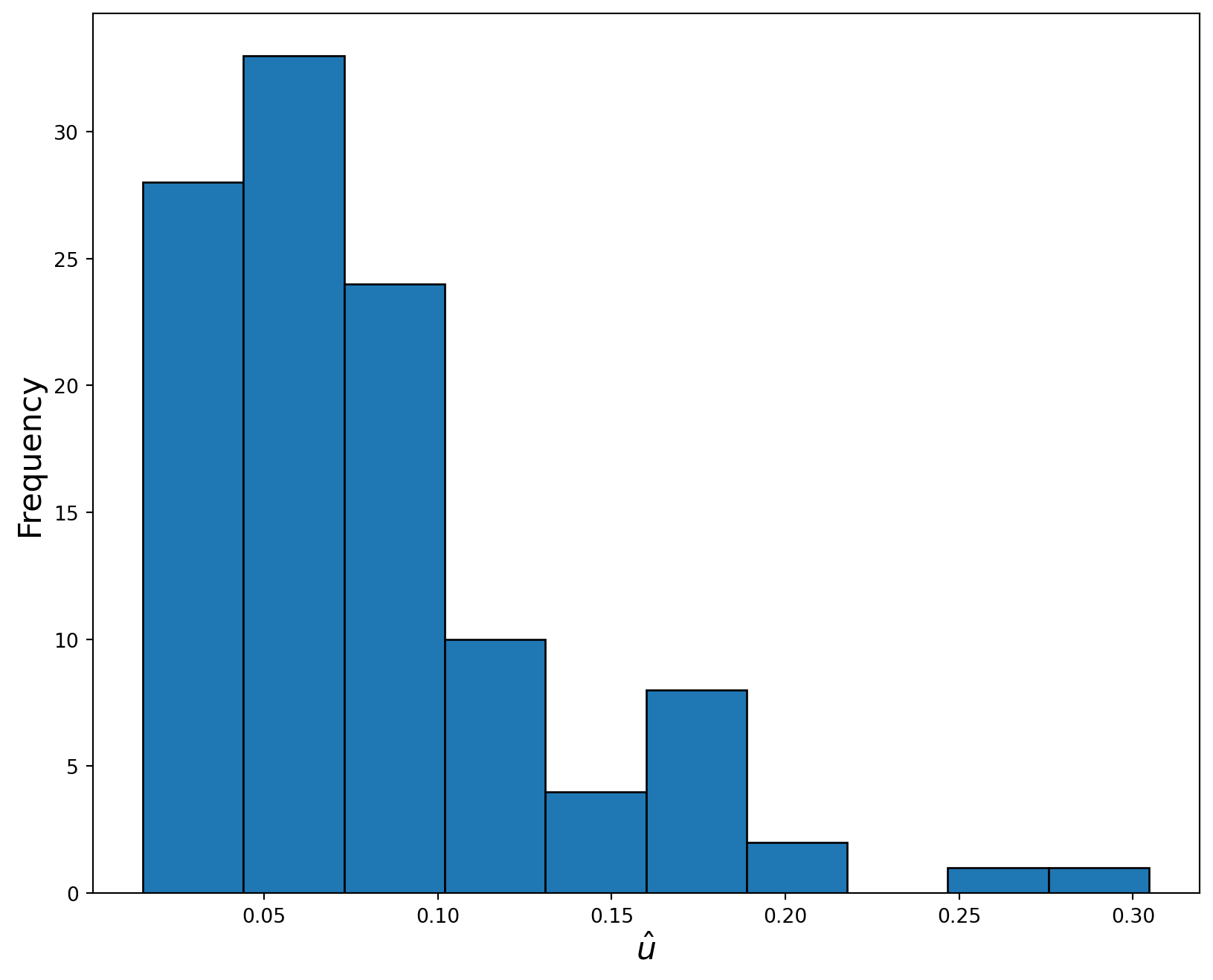
In order to obtain estimates of the inefficiencies, we generate the residuals and subtract their maximum from them. The result with a minus sign can be viewed as estimates of inefficiency \(u_i\). Alternatively, if we calculate \(\exp(-u_i)\), this will have the interpretation of production efficiency estimates, i.e. the percentage of potential electricity output actually produced by utility \(i\). Figure plots the histogram of technical efficiency estimates from the COLS model. The distribution appears to be right skewed.
import matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport statsmodels.formula.api as smfrom sklearn import linear_model
# Import dataproduction_data = pd.read_excel("cowing.xlsx") # Inputs and outputs are in Logarithms# Fit OLS modelcolsd = sm.ols( formula="y ~ X1 + X2 + X3", data=production_data[["y", "X1", "X2", "X3"]])colsd_fitted = colsd.fit()print(colsd_fitted.summary()) resids = colsd_fitted.resid u_star =-(resids - np.max(resids)) eff_colsd = np.exp(-u_star)# Plot a histogram of the technical efficiency estimatesfigure = plt.figure(figsize=(10, 8))plt.hist(eff_colsd, 10, edgecolor="k")plt.xlabel("$\exp(-\hat{u})$", fontsize=16)plt.ylabel("Frequency", fontsize=16)plt.show()
# Remove all previous function and variable definitions before the next exercise%reset
2.5 Exercise 2.5: MLE for the US utilities data
In thi exercise, we perform Maximum Likelihood Estimation (MLE) for a Cobb-Douglas production function using a sample of 111 steam-electric power plants.
import matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom scipy import statsfrom scipy.optimize import minimizedef log_density(coefs, y, x1, x2, x3): [alpha, beta1, beta2, beta3, sigma2u, sigma2v] = coefs[:] Lambda = np.sqrt(sigma2u / sigma2v) sigma2 = sigma2u + sigma2v sigma = np.sqrt(sigma2)# Composed errors from the production function equation eps = y - alpha - x1 * beta1 - x2 * beta2 - x3 * beta3# Compute the log density Den = ( (2/ sigma)* stats.norm.pdf(eps / sigma)* stats.norm.cdf(-Lambda * eps / sigma) ) logDen = np.log(Den)return logDendef loglikelihood(coefs, y, x1, x2, x3): logDen = log_density(coefs, y, x1, x2, x3) log_likelihood =-np.sum(logDen)return log_likelihooddef estimate(y, x1, x2, x3):# Starting values for MLE alpha =-11 beta1 =0.03 beta2 =1.1 beta3 =-0.01 sigma2u =0.01 sigma2v =0.0003 theta0 = np.array([alpha, beta1, beta2, beta3, sigma2u, sigma2v]) bounds = [(None, None) for x inrange(len(theta0) -2)] + [ (1e-6, np.inf), (1e-6, np.inf), ]# Minimize the negative log-likelihood using numerical optimization. MLE_results = minimize( fun=loglikelihood, x0=theta0, method="L-BFGS-B", tol =1e-6, options={"ftol": 1e-6, "maxiter": 1000, "maxfun": 6*1000}, args=(y, x1, x2, x3), bounds=bounds, ) theta = MLE_results.x log_likelihood = MLE_results.fun # Estimate standard errors delta =1e-6 grad = np.zeros((len(y), len(theta)))for i inrange(len(theta)): theta1 = np.copy(theta) theta1[i] += delta grad[:, i] = ( log_density(theta1, y, x1, x2, x3) - log_density(theta, y, x1, x2, x3) ) / delta OPG = grad.T @ grad ster = np.sqrt(np.diag(np.linalg.inv(OPG)))return theta, ster, log_likelihood
# Remove all previous function and variable definitions before the next exercise%reset
2.6 Exercise 2.6: MLE for models with heteroskedasticity
In this exercise we perform Maximum Likelihood Estimation for a Cobb-Douglas production function with heteroskedasticity (non-constant variance) in \(u\), that is \(\sigma^{2}_{ui}=\exp(\mathbf{z}_{i}'\omega_u)\), for 196 dairy farms. The output is the log amount of milk production and the inputs are labor hours (llabor), feed (lfeed), the number of cows (lcattle) and the land size of the farm (lland) all in logarithms. The environmental variable comp is IT expenditure as a percentage of total expenditure.
import numpy as npimport pandas as pdfrom scipy import statsfrom scipy.optimize import minimizedef log_density(coefs, y, x1, x2, x3, x4, z1):# Get parameters [alpha, beta1, beta2, beta3, beta4, omega0, omega1, sigma2v] = coefs[:] sigma2u = np.exp(omega0 + omega1 * z1) # Heteroskedastic sigma2u Lambda = np.sqrt(sigma2u / sigma2v) sigma2 = sigma2u + sigma2v sigma = np.sqrt(sigma2)# Composed errors from the production function equation eps = y - alpha - x1 * beta1 - x2 * beta2 - x3 * beta3 - x4 * beta4# Compute log-density Den = (2/ sigma * stats.norm.pdf(eps / sigma) * stats.norm.cdf(-Lambda * eps / sigma) ) Den = np.where( np.abs(Den) <1e-5, 1e-5, Den ) # Adjust small densities for numerical precision logDen = np.log(Den)return logDendef loglikelihood(coefs, y, x1, x2, x3, x4, z1):# Obtain the log likelihood logDen = log_density(coefs, y, x1, x2, x3, x4, z1) log_likelihood =-np.sum(logDen)return log_likelihooddef estimate(y, x1, x2, x3, x4, z1):""" Estimate model parameters by maximizing the log-likelihood function and compute standard errors. """# Starting values for MLE alpha =7.7 beta1 =0.1 beta2 =0.15 beta3 =0.75 beta4 =0.03 omega0 =-3 omega1 =-0.015# Coefficient for z1 sigma2v =0.005# Initial parameter vector theta0 = np.array([alpha, beta1, beta2, beta3, beta4, omega0, omega1, sigma2v]) bounds = [(None, None) for x inrange(len(theta0) -1)] + [(1e-6, np.inf)]# Minimize the negative log-likelihood using numerical optimization. MLE_results = minimize( fun=loglikelihood, x0=theta0, method="L-BFGS-B", tol =1e-6, options={"ftol": 1e-6, "maxiter": 1000, "maxfun": 6*1000, "maxcor": 500}, args=(y, x1, x2, x3, x4, z1) ) theta = MLE_results.x log_likelihood = MLE_results.fun *-1# Estimate standard errors delta =1e-6 grad = np.zeros((len(y), len(theta)))for i inrange(len(theta)): theta1 = np.copy(theta) theta1[i] += delta grad[:, i] = ( log_density(theta1, y, x1, x2, x3, x4, z1)- log_density(theta, y, x1, x2, x3, x4, z1) ) / delta OPG = grad.T @ grad # Outer product of gradient ster = np.sqrt(np.diag(np.linalg.inv(OPG)))return theta, ster, log_likelihood
# Import dataproduction_data = pd.read_csv("dairy.csv") # Inputs and outputs are in Logarithmsy = production_data["ly"].values[x1, x2, x3, x4] = [ production_data["llabor"].values, production_data["lfeed"].values, production_data["lcattle"].values, production_data["lland"].values,]# Environmental variablez1 = production_data["comp"]# Estimate coefficients via MLE and standard errors for SFA modelcoefs, sterr, logMLE = estimate(y, x1, x2, x3, x4, z1)Zscores = coefs / sterrPvalues =2* (1- stats.norm.cdf(np.abs(Zscores)))lower_ConfInt95 = stats.norm.ppf(0.025, loc=coefs, scale=sterr)upper_ConfInt95 = stats.norm.ppf(0.975, loc=coefs, scale=sterr)# Display the results as a tableresults = pd.DataFrame( columns=["Est", "StEr", "z-stat", "p-val", "[95%Conf.", "Interv]"], index=[r"$$\alpha$$","llabor","lfeed","lcattle","lland"," ",r"$$\omega_{0}$$","comp",r"$$\sigma^{2}_{v}$$", ],)coefs = np.round(coefs.reshape(-1, 1), 3)sterr = np.round(sterr.reshape(-1, 1), 3)Zscores = np.round(Zscores.reshape(-1, 1), 3)Pvalues = np.round(Pvalues.reshape(-1, 1), 3)lower_ConfInt95 = np.round(lower_ConfInt95.reshape(-1, 1), 3)upper_ConfInt95 = np.round(upper_ConfInt95.reshape(-1, 1), 3)# Get the production frontier parameter estimates, standard errors and confidence intervalsfrontier = np.concatenate( [ coefs[:5], sterr[:5], Zscores[:5], Pvalues[:5], lower_ConfInt95[:5], upper_ConfInt95[:5], ], axis=1,)# Get the parameters for the heteroskedastic technical inefficiency parameterizationOmegas = np.concatenate( [ coefs[5:7], sterr[5:7], Zscores[5:7], Pvalues[5:7], lower_ConfInt95[5:7], upper_ConfInt95[5:7], ], axis=1,)sigmas = np.array( [coefs[7], sterr[7], Zscores[7], Pvalues[7], lower_ConfInt95[7], upper_ConfInt95[7]]).Tprint("\nLog-Likelihood", round(logMLE, 3))results.iloc[0:5, :] = frontierresults.iloc[5, :] = np.full(shape=(1, 6), fill_value=" ")results.iloc[6:8, :] = Omegasresults.iloc[8:, :] = sigmasdisplay(results)
Log-Likelihood 110.545
Est
StEr
z-stat
p-val
[95%Conf.
Interv]
$$\alpha$$
7.701
0.493
15.617
0.0
6.734
8.667
llabor
0.105
0.046
2.282
0.023
0.015
0.196
lfeed
0.158
0.04
3.992
0.0
0.08
0.235
lcattle
0.752
0.064
11.703
0.0
0.626
0.878
lland
0.034
0.042
0.79
0.43
-0.05
0.117
$$\omega_{0}$$
-3.0
0.532
-5.636
0.0
-4.043
-1.957
comp
-0.016
0.094
-0.17
0.865
-0.2
0.168
$$\sigma^{2}_{v}$$
0.005
0.002
1.894
0.058
-0.0
0.009
# Remove all previous function and variable definitions before the next exercise%reset
2.7 Exercise 2.7: MLE of truncated normal distribution with \(\mu \neq 0\)
This exercise estimates a Cobb-Douglas production function with a truncated normal distribution for technical inefficiency with non-zero (constant) mean (\(\mu \neq 0)\) via maximum likelihood using the the dairy farm production data.
import matplotlib.pyplot as pltimport numdifftools as ndimport numpy as npimport pandas as pdfrom scipy import statsfrom scipy.optimize import minimizedef log_density(coefs, y, x1, x2, x3, x4):# Get parameters [alpha, beta1, beta2, beta3, beta4, mu, sigma2u, sigma2v] = coefs[:]# Composed errors from the production function equation eps = y - alpha - x1 * beta1 - x2 * beta2 - x3 * beta3 - x4 * beta4 sigma2 = sigma2u + sigma2v mu_star = (sigma2v * mu - sigma2u * eps) / sigma2 sigma2_star = (sigma2u * sigma2v) / sigma2 Den = stats.norm.pdf((eps + mu) / np.sqrt(sigma2)) / ( np.sqrt(sigma2)* ( stats.norm.cdf(mu / np.sqrt(sigma2u))/ stats.norm.cdf(mu_star / np.sqrt(sigma2_star)) ) ) Den = np.where( np.abs(Den) <1e-5, 1e-5, Den ) # Adjust small densities for numerical precision logDen = np.log(Den)return logDendef loglikelihood(coefs, y, x1, x2, x3, x4):# Obtain the log likelihood logDen = log_density(coefs, y, x1, x2, x3, x4) log_likelihood =-np.sum(logDen)return log_likelihooddef estimate(y, x1, x2, x3, x4):""" Estimate model parameters by maximizing the log-likelihood function and compute standard errors. """# Starting values for MLE alpha =7.7 beta1 =0.1 beta2 =0.15 beta3 =0.7 beta4 =0.03 sigma2u =0.17 sigma2v =0.005 mu =-1.2# Initial parameter vector theta0 = np.array([alpha, beta1, beta2, beta3, beta4, mu, sigma2u, sigma2v])# Bounds to ensure sigma2v and sigma2u are positive bounds = [(None, None) for x inrange(len(theta0) -2)] + [ (1e-6, np.inf), (1e-6, np.inf), ]# Minimize the negative log-likelihood using numerical optimization. MLE_results = minimize( fun=loglikelihood, x0=theta0, method="L-BFGS-B", tol =1e-6, options={"ftol": 1e-6, "maxiter": 1000, "maxfun": 6*1000, "maxcor": 500}, args=(y, x1, x2, x3, x4), bounds=bounds, ) theta = MLE_results.x # Estimated parameter vector logMLE = MLE_results.fun *-1# Log-likelihood at the solution# Estimate standard errors# Inverse of the Hessian approach hessian = nd.Hessian(f=loglikelihood, method="central", step=1e-5) ster = np.sqrt(np.diag(np.linalg.inv(hessian(theta, y, x1, x2, x3, x4))))return theta, ster, logMLE
/var/folders/q0/9kb46g7n1_57dfk7vtdsv8t4w169ch/T/ipykernel_41229/339382716.py:23: RuntimeWarning: divide by zero encountered in divide
stats.norm.cdf(mu / np.sqrt(sigma2u))
Est
StEr
z-stat
p-val
[95%Conf.
Interv]
$$\alpha$$
7.697
0.49
15.708
0.0
6.737
8.657
llabor
0.101
0.044
2.327
0.02
0.016
0.187
lfeed
0.152
0.038
4.013
0.0
0.078
0.227
lcattle
0.751
0.058
13.006
0.0
0.638
0.865
lland
0.044
0.039
1.116
0.265
-0.033
0.121
$$\mu$$
-1.2
4.387
-0.273
0.784
-9.799
7.399
$$\sigma^{2}_{u}$$
0.173
0.491
0.353
0.724
-0.789
1.136
$$\sigma^{2}_{v}$$
0.008
0.003
2.829
0.005
0.002
0.013
# Remove all previous function and variable definitions before the next exercise%reset
2.8 Exercise 2.8: MLE of truncated normal with \(\mu_{i} = z_{i}^{\prime}\delta\) and \(\sigma^{2}_{ui} = e^{({z_{i}^{\prime}\omega})}\)
This exercise estimates a Cobb-Douglas production function using a truncated normal distribution for technical inefficiency via maximum likelihood for 196 dairy farms. Marginal effects are also computed.
import numdifftools as ndimport numpy as npimport pandas as pdfrom scipy import statsfrom scipy.optimize import minimizedef log_density(coefs, y, x1, x2, x3, x4, z1):# get parameters [alpha,beta1,beta2,beta3,beta4, gamma0,gamma1,omega0,omega1,sigma2v,] = coefs[:10] mu = gamma0 + gamma1 * z1 sigma2u = np.exp(omega0 + omega1 * z1)# Composed errors from the production function equation eps = y - alpha - x1 * beta1 - x2 * beta2 - x3 * beta3 - x4 * beta4 sigma2 = sigma2u + sigma2v mu_star = (sigma2v * mu - sigma2u * eps) / sigma2 sigma2_star = (sigma2u * sigma2v) / sigma2 Den = stats.norm.pdf((eps + mu) / np.sqrt(sigma2)) / ( np.sqrt(sigma2)* ( stats.norm.cdf(mu / np.sqrt(sigma2u))/ stats.norm.cdf(mu_star / np.sqrt(sigma2_star)) ) ) Den = np.where( np.abs(Den) <1e-6, 1e-6, Den ) # Adjust small densities for numerical precision logDen = np.log(Den)return logDendef loglikelihood(coefs, y, x1, x2, x3, x4, z1):# Obtain the log likelihood logDen = log_density(coefs, y, x1, x2, x3, x4, z1) log_likelihood =-np.sum(logDen)return log_likelihooddef estimate(y, x1, x2, x3, x4, z1):""" Estimate model parameters by maximizing the log-likelihood function and compute standard errors. """# Starting values for MLE alpha =7.5 beta1 =0.1 beta2 =0.15 beta3 =0.7 beta4 =0.03 gamma0 =7 gamma1 =-1.5# Coefficient for z1 in non-constant mu equation omega0 =-3 omega1 =0.3# Coefficient for z1 in non-constant variance equation sigma2v =0.008# Initial parameter vector theta0 = np.array( [alpha, beta1, beta2, beta3, beta4, gamma0, gamma1, omega0, omega1, sigma2v] )# Bounds to ensure sigma2v and sigma2u are positive bounds = [(None, None) for x inrange(len(theta0) -1)] + [(1e-6, np.inf)] MLE_results = minimize( loglikelihood, theta0, method="L-BFGS-B", tol =1e-6, options={"ftol": 1e-6, "maxiter": 1000, "maxfun": 6*1000, "maxcor": 500}, args=(y, x1, x2, x3, x4, z1), bounds=bounds, ) theta = MLE_results.x logMLE = MLE_results.fun *-1# Standard errors# Inverse of the Hessian approach hessian = nd.Hessian(f=loglikelihood, method="central", step=1e-6) ster = np.sqrt(np.diag(np.linalg.inv(hessian(theta, y, x1, x2, x3, x4, z1))))return theta, ster, logMLE
/var/folders/q0/9kb46g7n1_57dfk7vtdsv8t4w169ch/T/ipykernel_41229/2332912828.py:25: RuntimeWarning: divide by zero encountered in divide
stats.norm.cdf(mu / np.sqrt(sigma2u))
Log-Likelihood 118.325
Est
StEr
z-stat
p-val
[95%Conf.
Interv]
$$\alpha$$
7.751
0.476
16.296
0.0
6.819
8.684
llabor
0.101
0.042
2.389
0.017
0.018
0.184
lfeed
0.145
0.037
3.948
0.0
0.073
0.218
lcattle
0.741
0.056
13.133
0.0
0.631
0.852
lland
0.053
0.038
1.41
0.159
-0.021
0.127
$$\delta_{0}$$
7.1
5.199
1.366
0.172
-3.09
17.289
$$\delta_{1}$$
-1.579
1.228
-1.286
0.198
-3.985
0.828
$$\omega_{0}$$
-3.654
1.04
-3.514
0.0
-5.692
-1.616
$$\omega_{1}$$
0.372
0.066
5.635
0.0
0.243
0.501
$$\sigma^{2}_{v}$$
0.008
0.002
4.717
0.0
0.005
0.012
2.8.1 Estimate Marginal Effects
# Marginal effect of comp on E(u)exogenous_data = np.column_stack([np.ones(len(z1)), z1])mu_vector = exogenous_data @ coefs[5:7]sigma_vector = np.sqrt(np.exp(exogenous_data @ coefs[7:9]))Lambda = mu_vector / sigma_vectorcdf = stats.norm.cdf(Lambda)pdf = stats.norm.pdf(Lambda)ratio = pdf / cdfmarginal_effects_Eu = coefs[6] * (1- Lambda * ratio - (ratio**2)) + coefs[8] * ( sigma_vector /2) * ((1+ (Lambda**2)) * ratio + (Lambda * ratio**2))average_marginal_effect_Eu =round(np.mean(marginal_effects_Eu), 5)print(f'The average marginal effect of the variable "comp" on the unconditional E(u) is {average_marginal_effect_Eu}')
The average marginal effect of the variable "comp" on the unconditional E(u) is -0.03591
# Remove all previous function and variable definitions before the next exercise%reset
2.9 Exercise 2.9: An SF model with the scaling property
This exercise estimates a Cobb-Douglas production function using a truncated normal distribution with the scaling property for technical inefficiency via maximum likelihood for 196 dairy farms.
import numdifftools as ndimport numpy as npimport pandas as pdfrom scipy import statsfrom scipy.optimize import minimizedef log_density(coefs, y, x1, x2, x3, x4, z1):# get parameters [alpha, beta1, beta2, beta3, beta4, gamma1, tau, cu, sigma2v] = coefs[:9]# Composed errors from the production function equation eps = y - alpha - x1 * beta1 - x2 * beta2 - x3 * beta3 - x4 * beta4 sigma2u_tilde = cu * np.exp(2* (gamma1 * z1)) u_tilde = tau * np.exp(gamma1 * z1) sigma2 = sigma2v + sigma2u_tilde u_star = (sigma2v * u_tilde - sigma2u_tilde * eps) / sigma2 sigma2_star = (sigma2v * sigma2u_tilde) / sigma2 Den = stats.norm.pdf((eps + u_tilde) / np.sqrt(sigma2)) / ( np.sqrt(sigma2)* ( stats.norm.cdf(u_tilde / np.sqrt(sigma2u_tilde))/ stats.norm.cdf(u_star / np.sqrt(sigma2_star)) ) ) Den = np.where( np.abs(Den) <1e-5, 1e-5, Den ) # Adjust small densities for numerical precision logDen = np.log(Den) # Log densityreturn logDendef loglikelihood(coefs, y, x1, x2, x3, x4, z1):# Obtain the log likelihood logDen = log_density(coefs, y, x1, x2, x3, x4, z1) log_likelihood =-np.sum(logDen)return log_likelihooddef estimate(y, x1, x2, x3, x4, z1):# Starting values for MLE alpha =7.7 beta1 =0.1 beta2 =0.15 beta3 =0.7 beta4 =0.03 gamma1 = (-0.008) # Coefficient for z1 in the scaling function h(.). No constant is included in the gamma parameter vector tau =-1# Mean of half-normal distribution common to all observations cu =0.15# Variance of half-normal distribution common to all observations sigma2v =0.008# Initial parameter vector theta0 = [alpha, beta1, beta2, beta3, beta4, gamma1, tau, cu, sigma2v] bounds = [(None, None) for x inrange(len(theta0) -2)] + [ (1e-6, np.inf), (1e-6, np.inf), ] MLE_results = minimize( loglikelihood, theta0, method="L-BFGS-B", tol =1e-6, options={"ftol": 1e-6, "maxiter": 1000, "maxfun": 6*1000, "maxcor": 500}, args=(y, x1, x2, x3, x4, z1), bounds=bounds, ) theta = MLE_results.x logMLE = MLE_results.fun *-1# Standard errors# Inverse of the Hessian approach hessian = nd.Hessian(f=loglikelihood, method="central", step=1e-6) ster = np.sqrt(np.diag(np.linalg.inv(hessian(theta, y, x1, x2, x3, x4, z1))))return theta, ster, logMLE
/var/folders/q0/9kb46g7n1_57dfk7vtdsv8t4w169ch/T/ipykernel_41229/2857292431.py:26: RuntimeWarning: divide by zero encountered in divide
stats.norm.cdf(u_tilde / np.sqrt(sigma2u_tilde))
Log-Likelihood 110.859
Est
StEr
z-stat
p-val
[95%Conf.
Interv]
$$\alpha$$
7.697
0.491
15.674
0.0
6.735
8.66
llabor
0.101
0.044
2.316
0.021
0.016
0.187
lfeed
0.153
0.038
4.019
0.0
0.078
0.228
lcattle
0.752
0.058
12.965
0.0
0.639
0.866
lland
0.043
0.039
1.08
0.28
-0.035
0.12
hscale
-0.007
0.047
-0.143
0.886
-0.099
0.085
$$\tau$$
-0.999
3.241
-0.308
0.758
-7.351
5.352
Cu
0.158
0.364
0.435
0.664
-0.554
0.871
$$\sigma^{2}_{v}$$
0.008
0.003
2.796
0.005
0.002
0.013
# Remove all previous function and variable definitions before the next exercise%reset
2.10 Exercise 2.10: An SF model with an exponential distribution for \(\mu_{i}\)
This exercise estimates a Cobb-Douglas production function with an exponential distribution for technical inefficiency via maximum likelihood for 196 dairy farms. To account for heteroskedasticity, the exponential distribution parameter is \(\eta^{2} = e^{({z}_{i}^{\prime}{\delta})}\).
import numdifftools as ndimport numpy as npimport pandas as pdfrom scipy import statsfrom scipy.optimize import minimizedef log_density(coefs, y, x1, x2, x3, x4, z1):# Get parameters [alpha, beta1, beta2, beta3, beta4, omega0, omega1, sigma2v] = coefs[:9] nu2 = np.exp(omega0 + omega1 * z1)# Composed errors from the production function equation eps = y - alpha - x1 * beta1 - x2 * beta2 - x3 * beta3 - x4 * beta4 cdf_term = stats.norm.cdf( (-eps / np.sqrt(sigma2v)) - (np.sqrt(sigma2v) / np.sqrt(nu2)) ) Den = (1/ np.sqrt(nu2)* np.exp((eps / np.sqrt(nu2)) + (sigma2v / (2* nu2)))* cdf_term ) logDen = np.log(Den)return logDendef loglikelihood(coefs, y, x1, x2, x3, x4, z1):# Obtain the log likelihood logDen = log_density(coefs, y, x1, x2, x3, x4, z1) log_likelihood =-np.sum(logDen)return log_likelihooddef estimate(y, x1, x2, x3, x4, z1):# Starting values for MLE alpha =7.5 beta1 =0.1 beta2 =0.15 beta3 =0.7 beta4 =0.03 omega0 =-4 omega1 =-0.005# Coefficient for z1 sigma2v =0.01# Initial parameter vector theta0 = [alpha, beta1, beta2, beta3, beta4, omega0, omega1, sigma2v]# Bounds to ensure sigma2v and sigma2u are > 0 bounds = [(None, None) for x inrange(len(theta0) -1)] + [(1e-4, np.inf)] MLE_results = minimize( loglikelihood, theta0, method="L-BFGS-B", tol =1e-6, options={"ftol": 1e-6, "maxiter": 1000, "maxfun": 6*1000, "maxcor": 500}, args=(y, x1, x2, x3, x4, z1), bounds=bounds, ) theta = MLE_results.x logMLE = MLE_results.fun *-1# Standard errors# Inverse of the Hessian approach hessian = nd.Hessian(f=loglikelihood, method="central", step=1e-6) ster = np.sqrt(np.diag(np.linalg.inv(hessian(theta, y, x1, x2, x3, x4, z1))))return theta, ster, logMLE
# Remove all previous function and variable definitions before the next exercise%reset
2.11 Exercise 2.11: Non-independence of \(u\) and \(v\)
This exercise estimates the MSLE of the diary farm production model under the Gaussiann copulabetween \(u\) and \(v\). Unlike in the application of Smith (2008), in our application the estimate of copula paramete \(\rho\) is large an statistically significant.
import numdifftools as ndimport numpy as npimport pandas as pdfrom scipy import statsfrom scipy.optimize import minimizedef log_density(coefs, y, x1, x2, x3, x4, us): N =len(y) S =len(us) [alpha, beta1, beta2, beta3, beta4, sigma2u, sigma2v, theta] = coefs[:] Rho = np.array([[1,theta], [theta,1]])try: R = np.linalg.cholesky(Rho) eps = y - alpha - x1*beta1 - x2*beta2 - x3*beta3 - x4*beta4 #Composed errors from the production function equation. eps_SxN = np.repeat(eps.values.reshape(-1,1), S, axis=1).T us_SxN = np.repeat(np.sqrt(sigma2u)*us.reshape(-1,1), N, axis=1) EpsPlusUs = eps_SxN + us_SxN DenEpsPlusUs = stats.norm.pdf(EpsPlusUs, loc=0, scale=np.sqrt(sigma2v)) CDFEpsPlusU = stats.norm.cdf(EpsPlusUs, loc=0, scale=np.sqrt(sigma2v)) CdfUs =2*(stats.norm.cdf(np.sqrt(sigma2u)*us, loc=0, scale=np.sqrt(sigma2u)) -0.5) simulated_copula_pdfs = np.zeros(shape=(S,N))for j inrange(N): U = np.concatenate([stats.norm.ppf(CDFEpsPlusU[:, j]).reshape(-1,1), stats.norm.ppf(CdfUs).reshape(-1,1)], axis=1) copula_den = stats.multivariate_normal.pdf(U, mean=np.zeros(2), cov=Rho)/np.prod(stats.norm.pdf(U), axis=1) simulated_copula_pdfs[:,j] = copula_den den = np.mean(simulated_copula_pdfs*DenEpsPlusUs, axis=0) logDen = np.log(den)except np.linalg.LinAlgError: logDen = np.ones(N)*-1e8#Assign an arbitrarily large log density if R is not positve definitereturn logDendef loglikelihood(coefs, y, x1, x2, x3, x4, us):# Obtain the log likelihood logDen = log_density(coefs, y, x1, x2, x3, x4, us) log_likelihood =-np.sum(logDen)return log_likelihooddef estimate(y, x1, x2, x3, x4): S =100# no. of simulated draws for the Integral us = stats.norm.ppf((stats.uniform.rvs(size=S, random_state=1234)+1)/2, 0, 1) # Simulated standard half-normal RVs alpha =7.5 beta1 =0.1 beta2 =0.15 beta3 =0.7 beta4 =0.03 sigma2u =0.2 sigma2v =0.06 intiial_theta =0.9 theta0 = np.array([alpha, beta1, beta2, beta3, beta4, sigma2u, sigma2v, intiial_theta])# Bounds to ensure sigma2v and sigma2u are > 0 bounds = [(None, None) for x inrange(len(theta0) -3)] + [(1e-6, np.inf), (1e-6, np.inf), (1e-6, np.inf)] MLE_results = minimize( loglikelihood, theta0, method="Nelder-Mead", options={"maxiter": 1000}, args=(y, x1, x2, x3, x4, us), bounds=bounds, ) theta = MLE_results.x logMLE = MLE_results.fun *-1# Standard errors# Inverse of the Hessian approach hessian = nd.Hessian(f=loglikelihood, method="central", step=1e-6) ster = np.sqrt(np.diag(np.linalg.inv(hessian(theta, y, x1, x2, x3, x4, us))))return theta, ster, logMLE